urdu-characters
📄 Complete ( 🇵🇰 ) Urdu Language Characters

![]()
![]()
Complete collection of Urdu language characters.
(46 Alphabets, 10 Digits, 6 Punctuations, 6 Diacritics)
Table of contents
- About Urdu Language
- What is Encoding
- What is Unicode
- Quick start
- Urdu vs Arabic Presentation form Characters Challenge
- Comparison of Unicode values of Urdu and Arabic characters
- Contributing
- Bugs and feature requests
- Contributors
- Copyright and license
About Urdu Language
Urdu is widely known as the national language of Pakistan, but it is also one of India’s 22 official languages. Modern Standard Urdu, once commonly known as a variant of Hindustani, a colloquial language combining the modified Sanskrit words found in Hindi with words brought to India via Persian, Arabic, Portuguese, Turkish and other languages, is a language with one of the most fascinating and complex histories in the world.
The Urdu alphabet is the right-to-left alphabet used for the Urdu language. It is a modification of the Persian alphabet known as Perso-Arabic, which is itself a derivative of the Arabic alphabet. The Urdu alphabet has up to 58 letters with 39 basic letters and no distinct letter cases, the Urdu alphabet is typically written in the calligraphic Nastaʿlīq script.
- http://www.panl10n.net/english/outputs/Pakistan/Urdu-Encoding-Collation.pdf
- http://www.bhurgri.com/bhurgri/downloads/PakLang.pdf
- http://jrgraphix.net/r/Unicode/0600-06FF
- https://www.unicode.org/charts/PDF/U0600.pdf
- https://www.unicode.org/cldr/charts/34/collation/ur.html
- http://www.unics.uni-hannover.de/nhtcapri/urdu-alphabet.html
- https://r12a.github.io/scripts/arabic/urdu
- https://blogs.transparent.com/urdu/a-short-history-of-urdu/
What is Encoding
Character encoding may be defined as assigning a unique number to each language character to be processed by the computer. Whenever a character is input from keyboard or other input devices, this particular code is generated internally in the computer. Arbitrary encoding may be defined for any application (e.g. 80 for letter ‘a’, 81 for letter ‘b’). However, if different vendors are defining arbitrary encodings, their encodings may not agree with one another.
With the advent of the Internet, it has now become increasingly essential to standardize the encoding scheme because users are accessing data created by a variety of sources through web browsers (a single application). Realizing the significance of standardizing encoding, work was done early for English and American Standard Code for Information Interchange (ASCII) was defined in 1968. This standard had 128 slots defined using 7 bits by American National Standards Institute (ANSI).
What is Unicode
Initially most documentation was done in a single language, therefore 8-bit single language code pages served the need. However, in 1990s, with increasing needs for multi-lingual documents (where one could require Japanese and Arabic in the same document), it was realized that defining 8-bit code pages were not a scalable solution. Adding code pages for various languages and scripts and using them together in one application created a lot of difficulty and complexity in processing because users had to keep toggling between them.
To address this issue, major vendors got together and created Unicode consortium (www.unicode.org). This consortium started working on developing a singular, unified and universal code chart which would contain all characters of all languages. As 8-bit (256 slots) code pages were insufficient for this requirement, Unicode character encoding standard was developed using 16 bits (65536 slots). This space has been divided to cater to various scripts and thus bypassed the need for toggling for different languages.
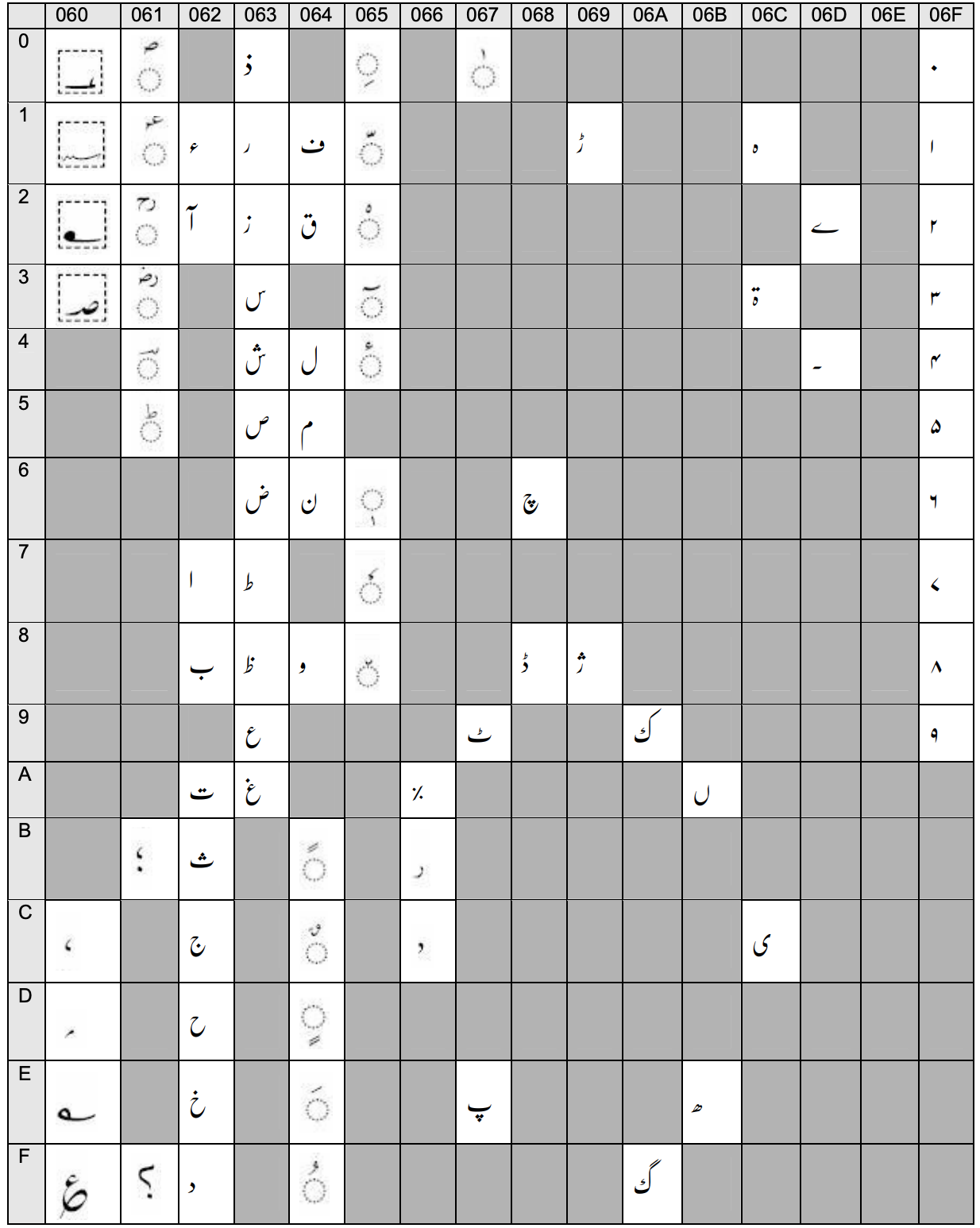
Urdu Unicode Range(0600-06ff)
Arabic is a superset of Urdu, Persian, and Sindhi.
Urdu, Arabic, Persian, Sindhi, all occupy the same range i.e. 0600-06FF. But different code points for some
different characters.
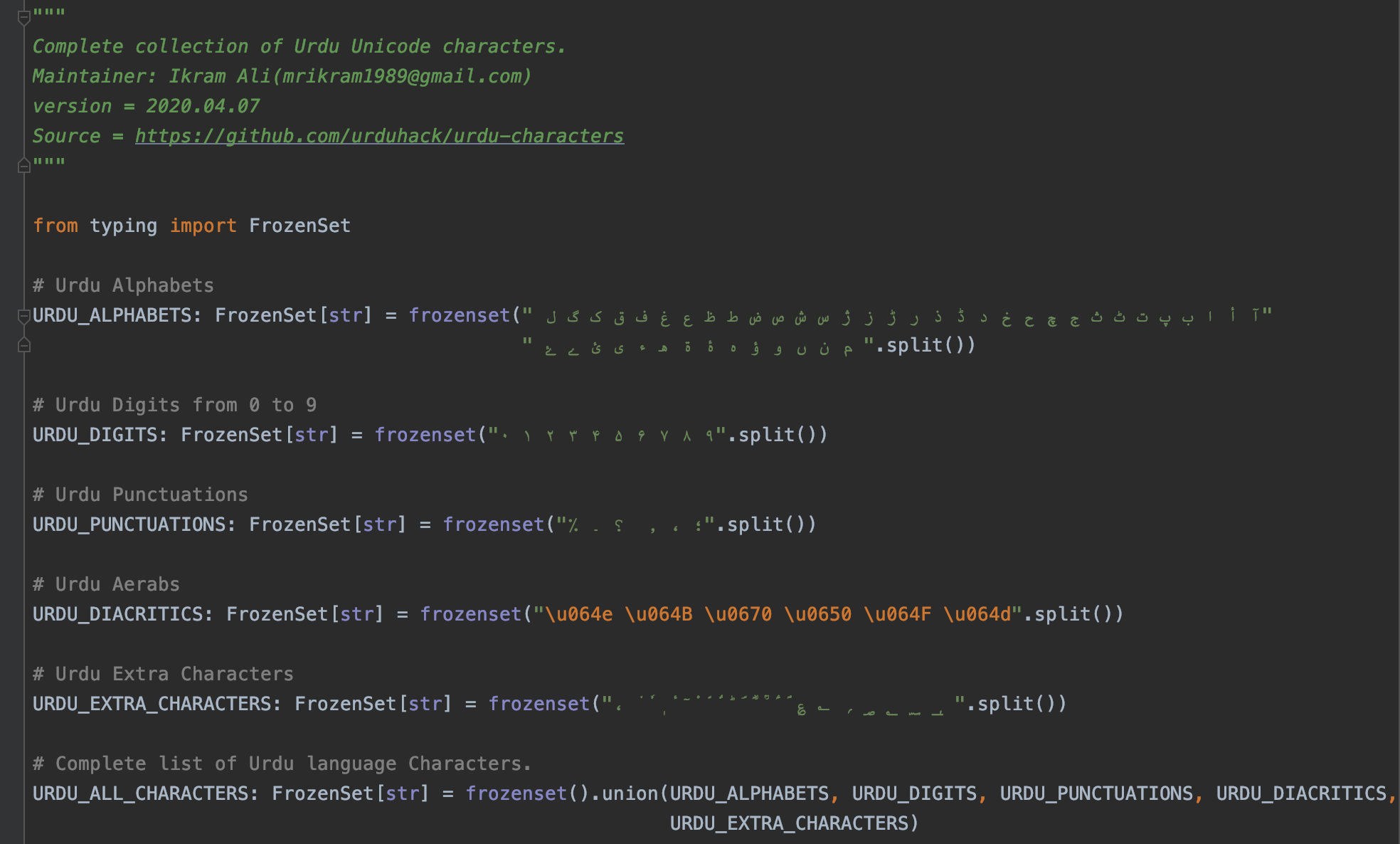
urdu_characters.py Content
Quick start
urdu_characters.py contains complete urdu characters with unicode Range (0600 - 06ff). This file contains three type of characters list.
URDU_DIGITSset contains 10 URDU DIGITS.URDU_ALPHABETset contains 44 characters.URDU_PUNCTUATIONset contains 6 PUNCTUATION characters.DIACRITICSset contains 4 basic characters.
Urdu vs Arabic Presentation form Characters Challenge
Unicode provides support for Urdu language but there is a problem we have to cater in order to utilise that support. The Urdu is incorporated in Arabic language’s block in the Unicode table as Urdu is derived from Arabic script. This makes things a little bit complicated for computer scientists trying to develop applications for Urdu language.
For example consider a word “خاموشی”, now if we see the codes at the back-end for this word we can find two different sets of codes form Unicode table.
Set of codes #1
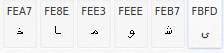
Set of codes #2

Now the problem is how do we know on which codes we have to train our model on? If we train our model on a specific range (Urdu 0600-06ff) and our dataset has some words formed using the Arabic set of codes then our application will fail to recognize those words resulting in low accuracy. This redundancy in codes of words hinders us to achieve a high accuracy.
So how do we handle this issue? You can go up and look at the Urdu Unicode Range table. Unicode has standardized this range (0600-06ff) for Urdu only. So all we need to do is to do some data pre-processing before running any alogrithm on data. For each word in data having redundant codes, we can replace that word with the same standardized Urdu word belonging to the range 0600 to 06ff. That’s it!
Urdu Characters Shapes
Urdu characters take on different forms based on the position they are used inside a word. Like an urdu character used at the start of a word will have a different shape and the same character used in the middle or at the end of a word will have a completely different shape. This is only concerned with the font shape for that character. For illustration purpose, let’s take an example of urdu character “ﻑ”. Now notice the difference in “ﻑ” shape.
- Used at the Start: “آفاق”
- Used in the middle: “مفاحمت”
- Used at the End: “کیف”
- Isolated Use: “موصوف”
As you would have noticed “ﻑ” takes on a different shape based on its position of usage.
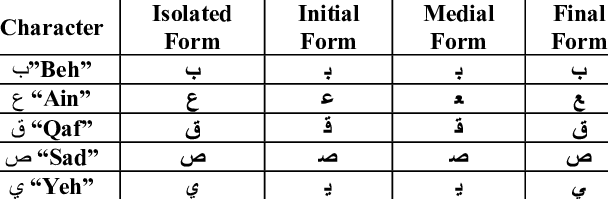
Urdu/Arabic Character Presentation Fonts
Now to get a bit more understanding of the above part, let’s look at the unicode range for combined characters. These combined characters are given a unicode range separately. This range was defined for the intuition purpose only. How two characters appear when they are combined. It has more to do with the usage of characters in different positions rather than the context the character is used in. In arabic “Qaida”, for teaching purpose, it is taught how two characters like “ل” and “ح” when combined will appear like “لح”. This “لح” is given a new unicode FC40. There wil hardly be any keyboard or a system which will use these combined characters so this just to show different presentation forms of a character. For more illustrative purpose, look at the below links.
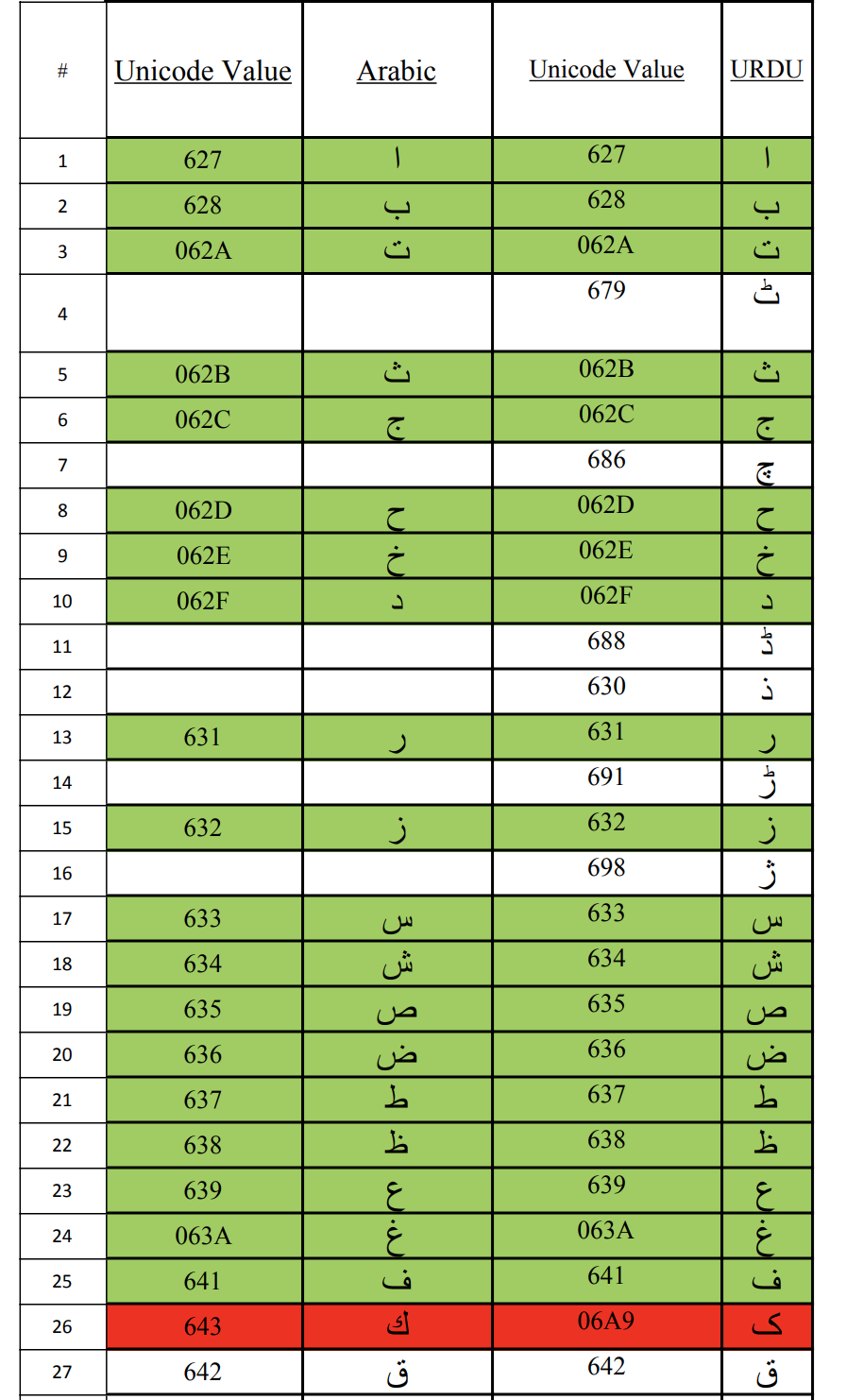
Comparison of Unicode values of Urdu and Arabic characters
Thanks to (https://github.com/urdutext/UrduArabicCompare)
CSV file (https://github.com/urduhack/urdu-characters/blob/master/img/Urdu_Arabic_Unicode_comparison.csv)
Contributing
All contributions are more than welcomed. Contributions may close an issue, fix a bug (reported or not reported), improve the existing code and so on.
Bugs and feature requests
Have a bug or a feature request? If you wish to remove or update some thing, please file an issue first before sending a PR on the repo. [please open a new issue]
Contributors
Special thanks to everyone who contributed to getting the UrduHack to the current state.
Backers 
Thank you to all our backers! 🙏 [Become a backer]

Sponsors 
Support this project by becoming a sponsor. Your logo will show up here with a link to your website. [Become a sponsor]
![]()
![]()
Copyright and license
Code released under the MIT License.